/ projects / glados
GLaDOS
Local-LLM writing assistant for daily home use, no cloud, no subscription
Built into it
- Hermes 4 70B via Lemonade SDK
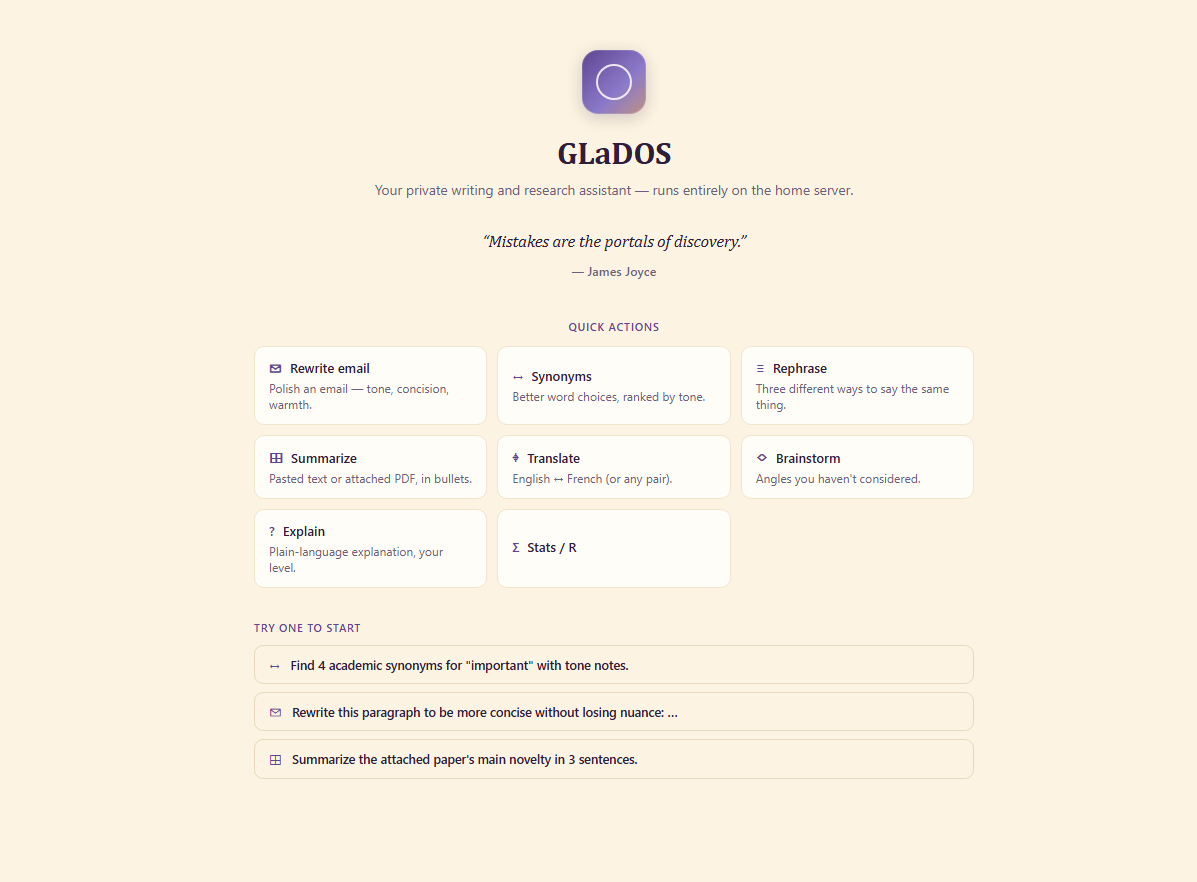
- Quick-action chips for daily moves
- Podman Quadlet single-container deploy
Problem
Most “AI assistant for a non-technical user” stories end with ChatGPT and a monthly bill. For someone who works with sensitive research material — paper drafts, peer-review feedback, grant submissions — the better answer is an assistant that runs locally, doesn’t send data anywhere, and stays available when the home internet is down. That’s an engineering match for the problem shape, not a privacy stunt.
Approach
GLaDOS is a privately-hosted chat assistant running on a Framework Desktop, served over Tailscale to the home network. FastAPI on Python 3.13 fronts Lemonade SDK, which runs Hermes 4 70B locally. Frontend is React + Vite + TypeScript with Zustand state; SQLite in WAL mode for persistence; PyMuPDF for PDF text extraction; Server-Sent Events for response streaming.
The whole thing deploys as a single Podman Quadlet container on Bluefin-DX with a SELinux-labeled bind mount for state. Langfuse is wired in from day one — corpus capture is the prerequisite for any future quality work, so the trace pipeline isn’t a phase-two add-on.
[Framework Desktop, home LAN]
├── Podman Quadlet container
│ ├── FastAPI (Python 3.13)
│ └── React/Vite frontend (served from same container)
├── Lemonade SDK :13305 → Hermes 4 70B :18002
└── SQLite WAL @ /var/lib/glados/
Reached via Tailscale from any household device. No public ingress.
The UI is purpose-built, not a generic chat surface. Quick-action chips cover the high-frequency moves — rewrite email, summarize PDF, rephrase, translate, brainstorm, explain, stats help — so the daily flow is one click instead of three sentences of prompt engineering. Hybrid chat-as-canvas layout: the conversation isn’t the only first-class artifact.
Outcome
When the cable internet drops mid-edit on a grant draft, the assistant keeps working. Daily-use chat that doesn’t leak data, doesn’t go down with the WAN link, and doesn’t add a subscription line item — roughly comparable to a hosted assistant for the writing and research workflow, with full control over what the model sees and remembers.
What’s next
Per-conversation system prompts — separate personas for grant writing, paper review, and translation — and a corpus-export pipeline so the Langfuse traces become evaluation data instead of just observability. RAG and code-routing are explicitly deferred until the dogfood signal from v1 says they’re worth the complexity.
/ related · 03
Other projects
- 01
BASTION
KQL investigation toolkit that ends the rebuild-from-scratch loopHTML JavaScript Python FastAPIActive - 02
CARL
Offline SOC knowledge base that captures what lives in analysts' headsHTML JavaScript Python FastAPIActive - 03
KQL Sentinel Lab
Synthetic Sentinel environment for analysts to practice on real attack dataHTML JavaScript Python FastAPIActive