/ projects / prompt-forge
Prompt Forge
Generate structured Claude system prompts for SOC analyst workflows
Built into it
- 8 pre-built SOC task templates
- General + SOC-focused editions
- Context-field substitution engine
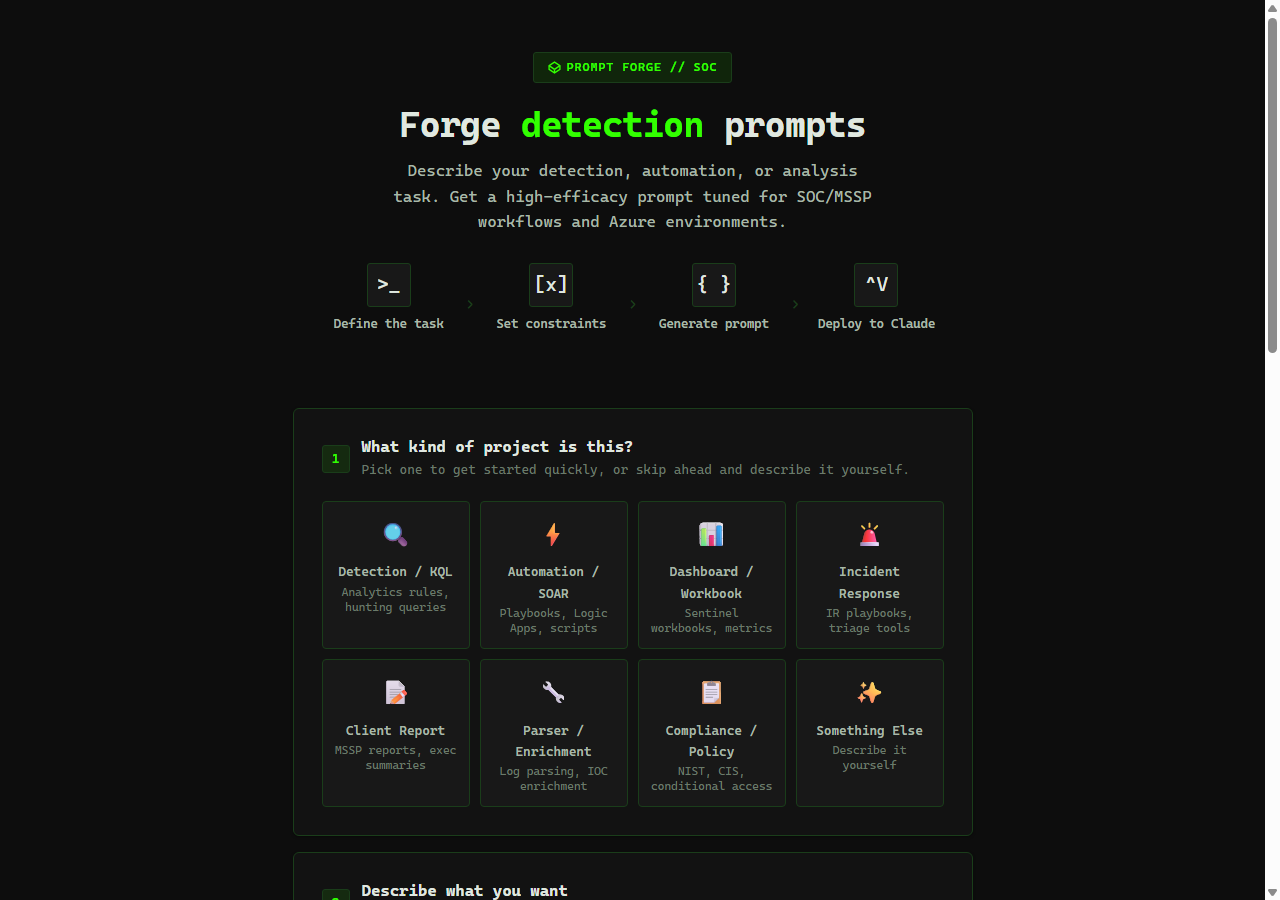
Problem
Analysts using LLMs ad-hoc for SOC tasks produce inconsistent outputs because every analyst writes prompts differently. One analyst’s “summarize this alert” comes back as a paragraph; another’s comes back as a bulleted list with severity calls. For tasks where the output is a versioned artifact — investigation notes, escalation summaries, threat-intel writeups — that variance is a process problem, not a model problem.
Approach
Prompt Forge is a single-file HTML tool that generates structured system prompts for SOC tasks. Pick a template, fill in the context fields (alert type, severity, entities, scope), and it emits a ready-to-use instruction set in a consistent format. Two editions ship together: a general builder for any task, and a SOC edition with pre-built templates for alert triage, threat-intel summary, incident writeup, and analyst coaching.
[Template: Alert Triage Summary]
Task: Triage a Sentinel alert.
Context:
- Alert type: {{alert_type}}
- Severity: {{severity}}
- Affected entity: {{entity}}
- Tenant: {{tenant}}
Output format:
1. One-sentence summary
2. Key entities and their roles
3. Recommended next investigation step
4. Severity confirmation or downgrade rationale
Constraints:
- No speculation beyond evidence in the alert payload
- Cite the data point for each claim
- Flag any missing context required to complete the triage
Outcome
The prompt becomes a versioned artifact instead of something each analyst reinvents. Two analysts working similar alerts produce comparable, reviewable output — and when a model update changes behavior, the regression is visible because the input is fixed.
What’s next
Per-template eval sets are the next step: run each template against a synthetic alert corpus and score the outputs, so I can catch prompt regressions before they reach the analyst floor. The hard part is the corpus, not the eval harness.
/ related · 03
Other projects
- 01
BASTION
KQL investigation toolkit that ends the rebuild-from-scratch loopHTML JavaScript Python FastAPIActive - 02
CARL
Offline SOC knowledge base that captures what lives in analysts' headsHTML JavaScript Python FastAPIActive - 03
KQL Sentinel Lab
Synthetic Sentinel environment for analysts to practice on real attack dataHTML JavaScript Python FastAPIActive